
读论文_PCA_主曲线
25 Dec 2019PCA
Principal components analysis, 看了一下网上的一些科普文章以及志华 の 西瓜书.
来源 http://blog.codinglabs.org/articles/pca-tutorial.html
目的 :
对数据进行降维, 例如, 对于淘宝店铺的数据, 将其中某一天的数据表示为 (日期, 浏览量, 访客数, 下单数, 成交数, 成交金额). 从经验可以知道, “浏览量” 和 “访客数” 往往具有较强的相关关系, 而 “下单数” 和 “成交数” 也具有较强的相关关系. 这里非正式地使用 “相关关系” 这个词, 可以直观理解为 “当某一天这个店铺的浏览量较高 (或较低) 时, 我们应该很大程度上认为这天的访客数也较高 (或较低)”, 这种情况表明, 如果删除浏览量或访客数其中一个指标, 应该并不会丢失太多信息. 因此可以删除其中一个, 以降低算法复杂度.
矩阵表示
下面的矩阵知识简直太基础了, 足以说明我的数学知识储备基本为 0.
内积与投影
两个维数为 n 的向量 a, b, 他们的内积可以表示为点乘, a·b = a1b1 + a2b2 + … + anbn = |a|·|b|cosα. 可以说 a 和 b 的内积表示 a 与 b 的内积等于 a 到 b 的投影长度乘以 b 的模. 设向量 b 的模为1, 则两向量的内积值等于 a 向 b 所在直线投影的矢量长度.
基
向量 (x, y) 实际上可以用线性组合来表示 x(1, 0)T + y(0, 1)T, 要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值, 就可以了. 只不过我们经常省略第一步而默认以(1,0)和(0,1)为基. 实际上任何两个线性无关的二维向量都可以成为一组基.
一般来说, 我们希望基的模是 1, 因为从内积的意义可以看到, 如果基的模是 1, 那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了. 进行新的基下的坐标转换的时候, 只要分别计算 (x, y) 在两个基的内积即可.
基变换的矩阵表示
假设原始的向量为 (3, 2), 那么在新的基
\[(1/ \sqrt{2}, 1/ \sqrt{2}) 和 (-1/ \sqrt{2}, 1/ \sqrt{2})\](注意两个基的模都为1, 并且他们的内积为 0, 说明垂直), 下的表示可以用矩阵表示为:
\[\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 3 \\ 2 \end{pmatrix} = \begin{pmatrix} 5/\sqrt{2} \\ -1/\sqrt{2} \end{pmatrix}\]非常好! 其中矩阵的两行分别为两个基, 乘以原向量, 其结果刚好为新基的坐标. 稍微推广一下, 如果我们有 m 个二维向量,只要将二维向量按列排成一个两行 m 列矩阵, 然后用 “基矩阵” 乘以这个矩阵, 就得到了所有这些向量在新基下的值. 例如(1, 1), (2, 2), (3,3), 想变换到刚才那组基上, 可以这样表示:
\[\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \\ 1 & 2 & 3 \end{pmatrix} = \begin{pmatrix} 2/\sqrt{2} & 4/\sqrt{2} & 6/\sqrt{2} \\ 0 & 0 & 0 \end{pmatrix}\]再次推广, 如果有 M 个 N 维向量, 想将其变换为由 R 个 N 维向量表示的新空间中, 那么首先将 R个基按行组成矩阵 A, 然后将向量按列组成矩阵 B, 那么两矩阵的乘积 AB 就是变换结果, 其中AB 的第 m 列为 B 中第 m 列变换后的结果.
\[\begin{pmatrix} p_1 \\ p_2 \\ \vdots \\ p_R \end{pmatrix} \begin{pmatrix} a_1 & a_2 & \cdots & a_M \end{pmatrix} = \begin{pmatrix} p_1a_1 & p_1a_2 & \cdots & p_1a_M \\ p_2a_1 & p_2a_2 & \cdots & p_2a_M \\ \vdots & \vdots & \ddots & \vdots \\ p_Ra_1 & p_Ra_2 & \cdots & p_Ra_M \end{pmatrix}\]这段话中
其中 AB 的第 m 列为 B 中第 m 列变换后的结果原文的作者写成了A 中 m 列变换后的结果, 显然是错误的, 后来转载的都没有改正
其中 pi 是一个行向量, 表示第 i 个基, aj 是一个列向量, 表示第 j 个原始数据记录.
注意, 注意, 这里 R 可以小于 N , 而 R 决定了变换后数据的维数. 也就是说, 可以将一个 N 维数据变换到更低维度的空间中, 变换后的维度取决于基的数量 R. 因此这种矩阵相乘的表示也可以表示降维变换.
说的简直太好了, 我都能理解.
上述分析同时给矩阵相乘找到了一种物理解释: 两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去. 更抽象的说, 一个矩阵可以表示一种线性变换.
这种说法似乎有点问题, 见这篇文章的推导, 结论是只有左边的矩阵中的列向量两两正交的单位向量才能够这样理解.
假设我们的数据由五条记录组成, 将它们表示成矩阵形式:
\[\begin{pmatrix} 1 & 1 & 2 & 4 & 2 \\ 1 & 3 & 3 & 4 & 4 \end{pmatrix}\]其中每一列为一条数据记录, 而一行为一个字段. 为了后续处理方便, 我们首先将每个字段内所有值都减去字段均值, 其结果是将每个字段都变为均值为0:
\[\begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}\]五条数据在平面直角坐标系内的样子:
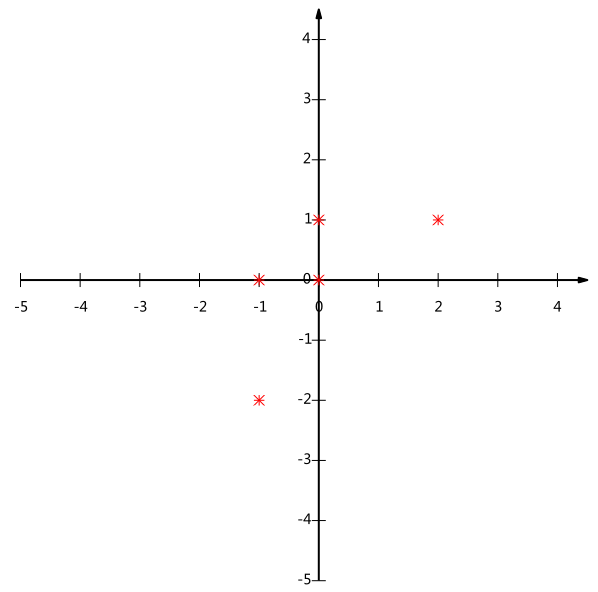
现在问题是: 如何使用一维来表示这些数据, 又希望尽量保留原始的信息?
这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录. 是一个实际的二维降到一维的问题.
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢? 一种直观的看法是: 希望投影后的投影值尽可能分散.
以上图为例, 可以看出如果向x轴投影, 那么最左边的两个点会重叠在一起, 中间的两个点也会重叠在一起, 于是本身四个各不相同的二维点投影后只剩下两个不同的值了, 这是一种严重的信息丢失, 同理, 如果向y轴投影最上面的两个点和分布在x轴上的两个点也会重叠. 所以看来x和y轴都不是最好的投影选择, 我们直观目测, 如果向通过第一象限和第三象限的斜线投影, 则五个点在投影后还是可以区分的.
方差
分散程度可以用数学上的方差来表述, 一个字段 (矩阵中的一行) 的方差可以看做是每个元素与字段均值的差的平方和的均值:
\[Var(a)=\frac{1}{m}\sum_{i=1}^m{(a_i-\mu)^2}\]前面我们已经将 μ 搞到 0 了, 上个式子就变成:
\[Var(a)=\frac{1}{m}\sum_{i=1}^m{a_i ^ 2}\]现在的目标就变成了, 寻找一个一维基, 使得所有数据变换为这个基上的坐标表示后方差值最大.
协方差
对于上面二维降成一维的问题来说, 找到那个使得方差最大的方向就可以了. 不过对于更高维, 还有一个问题需要解决. 考虑三维降到二维问题, 与之前相同, 首先我们希望找到一个方向使得投影后方差最大, 这样就完成了第一个方向的选择, 继而我们选择第二个投影方向。
如果我们还是单纯只选择方差最大的方向, 很明显这个方向与第一个方向应该是 “几乎重合在一起”, 这样的维度是没有用的, 因此, 应该有其他约束条件. 从直观上说, 让两个字段尽可能表示更多的原始信息, 我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为0,则:
\[Cov(a,b)=\frac{1}{m}\sum_{i=1}^m{a_ib_i}\]在字段均值为0的情况下,两个字段的协方差为其内积除以元素数 m.
当协方差为0时, 表示两个字段完全独立. 为了让协方差为 0, 我们选择第二个基时只能在与第一个基正交的方向上选择. 因此最终选择的两个方向一定是正交的.
现在, 我们得到了降维问题的优化目标: 将一组 N 维向量降为 R 维 (R 大于 0, 小于 N), 目标是选择 R 个单位 (模为1) 正交基, 使得原始数据变换到这组基上后, 各字段两两间协方差为 0, 而字段的方差则尽可能大 (在正交的约束下, 取最大的 K 个方差).
层层递进, 写的太好了.
那么如何实现上面的目标呢?
协方差矩阵
最终要达到的目的与字段内方差及字段间协方差有密切关系, 假设我们只有a和b两个字段, 那么将它们按行组成矩阵 X:
\[X=\begin{pmatrix} a_1 & a_2 & \cdots & a_m \\ b_1 & b_2 & \cdots & b_m \end{pmatrix}\]然后我们用 X 乘以 X 的转置,并乘上系数 1/m:
\[\frac{1}{m}XX^\mathsf{T}=\begin{pmatrix} \frac{1}{m}\sum_{i=1}^m{a_i^2} & \frac{1}{m}\sum_{i=1}^m{a_ib_i} \\ \frac{1}{m}\sum_{i=1}^m{a_ib_i} & \frac{1}{m}\sum_{i=1}^m{b_i^2} \end{pmatrix}\]奇迹出现了! 这个矩阵对角线上的两个元素分别是两个字段的方差, 而其它元素是a和b的协方差. 两者被统一到了一个矩阵中.
将这种方法推广到一般的情况:
设我们有 m 个 n 维数据记录, 将其按列排成 n 乘 m 的矩阵 X, 设
\[C=\frac{1}{m}XX^\mathsf{T}\]则 C 是一个对称矩阵, 其对角线分别个各个字段的方差, 而第 i 行 j 列和 j 行 i 列元素相同, 表示 i 和 j 两个字段的协方差.
协方差矩阵对角化
设原始数据矩阵X对应的协方差矩阵为 C, 而 P 是一组基按行组成的矩阵, 设 Y = PX, 则 Y 为 X 对 P 做基变换后的数据. 设 Y 的协方差矩阵为 D, D 与 C 的可以表示为:
\[\begin{array}{l l l} D & = & \frac{1}{m}YY^\mathsf{T} \\ & = & \frac{1}{m}(PX)(PX)^\mathsf{T} \\ & = & \frac{1}{m}PXX^\mathsf{T}P^\mathsf{T} \\ & = & P(\frac{1}{m}XX^\mathsf{T})P^\mathsf{T} \\ & = & PCP^\mathsf{T} \end{array}\]只用到了进行矩阵转置的公式, easy.
现在我们的目标就变成了寻找一个矩阵 P, 使得 PCPT, 是一个对角矩阵, 并且对角元素按从大到小依次排列, 那么 P 的前 R 行就是要寻找的基, 用 P 的前 R 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 R 维并满足上述优化条件.
由上文知道, 协方差矩阵C是一个是对称矩阵, 实对称矩阵有两个非常好的性质:
- 实对称矩阵不同特征值对应的特征向量必然正交.
- 设特征向量 λ 重数为 r, 则必然存在 r 个线性无关 (正交) 的特征向量对应于 λ, 因此可以将这 r 个特征向量单位正交化.
由上面两条可知, 一个 n 行 n 列的实对称矩阵一定可以找到 n 个单位正交特征向量, 设这 n 个特征向量为 e1, e2, …, en, 将其按列组成矩阵:
\[E=\begin{pmatrix} e_1 & e_2 & \cdots & e_n \end{pmatrix}\]则对协方差矩阵C有如下结论:
\[E^\mathsf{T}CE=\Lambda=\begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix}\]其中 Λ 为为对角矩阵,其对角元素为各特征向量对应的特征值 (可能有重复).
那么有:
\[P=E^\mathsf{T}\]P 是协方差矩阵的特征向量单位化后按行排列出的矩阵, 其中每一行都是 C 的一个特征向量. 如果将 P 按照 Λ 中特征值从大到小将特征向量从上到下排列, 则用P的前 R 行组成的矩阵乘以原始数据矩阵 X, 就得到了我们需要的降维后的数据矩阵 Y.
以上内容是 PCA 的数学原理部分.
PCA 实例
总结一下 PCA 算法的步骤:
设有 m 条 n 维数据:
- 将原始数据按列组成 n 行 m 列矩阵 X
- 将 X 的每一行 (代表一个属性字段) 进行零均值化, 即减去这一行的均值
- 求出 X 的协方差矩阵 C
- 求出协方差矩阵的特征值及特征向量
- 将特征向量按对应特征值大小从上到下按行排列成矩阵, 取前 k 行组成矩阵 P
- Y = PX 即为降维到 k 维后的数据
以上面的 5 条 2 维数据为例, 将其降为 1 维, 已经满足步骤 2, 进行步骤 3:
\[C=\frac{1}{5}\begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}\begin{pmatrix} -1 & -2 \\ -1 & 0 \\ 0 & 0 \\ 2 & 1 \\ 0 & 1 \end{pmatrix}=\begin{pmatrix} \frac{6}{5} & \frac{4}{5} \\ \frac{4}{5} & \frac{6}{5} \end{pmatrix}\]然后求出协方差的特征值和特征向量:
\[\lambda_1=2,\lambda_2=2/5\]对应的特征向量分别是:
\[c_1\begin{pmatrix} 1 \\ 1 \end{pmatrix}, c_2\begin{pmatrix} -1 \\ 1 \end{pmatrix}\]其中对应的特征向量分别是一个通解, c1和c2可取任意实数. 那么标准化后的特征向量为:
\[\begin{pmatrix} 1/\sqrt{2} \\ 1/\sqrt{2} \end{pmatrix},\begin{pmatrix} -1/\sqrt{2} \\ 1/\sqrt{2} \end{pmatrix}\]注意, 注意, 此时 P = ET 所以 P 就变成了:
\[P=\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}\]验证协方差矩阵C的对角化 (只是验证, 对结果没啥用):
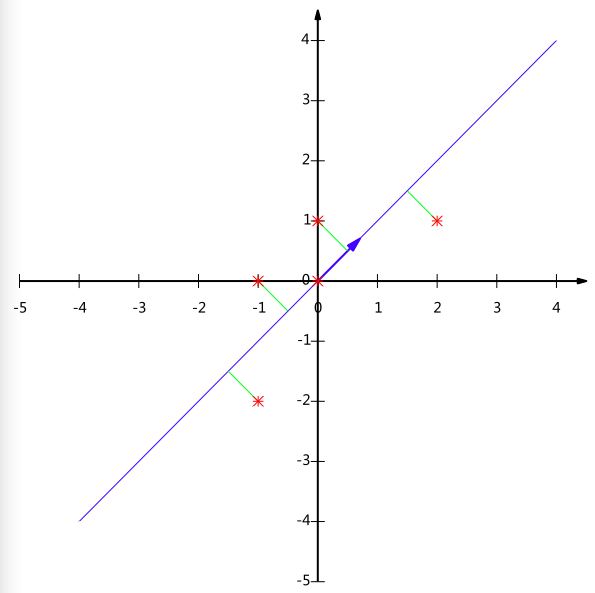
\[PCP^\mathsf{T}=\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}\begin{pmatrix} 6/5 & 4/5 \\ 4/5 & 6/5 \end{pmatrix}\begin{pmatrix} 1/\sqrt{2} & -1/\sqrt{2} \\ 1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}=\begin{pmatrix} 2 & 0 \\ 0 & 2/5 \end{pmatrix}\]降到一维, 只需要第一行:
\[Y=\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}\begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}=\begin{pmatrix} -3/\sqrt{2} & -1/\sqrt{2} & 0 & 3/\sqrt{2} & -1/\sqrt{2} \end{pmatrix}\]画图表示:
PCA 本质上是将方差最大的方向作为主要特征, 并且在各个正交方向上将数据 “离相关”, 也就是让它们在不同正交方向上没有相关性.
PCA 也存在一些限制, 例如它可以很好的解除线性相关 (通过协方差解决), 但是对于高阶相关性就没有办法了, 对于存在高阶相关性的数据, 可以考虑 Kernel PCA, 通过 Kernel 函数将非线性相关转为线性相关. 另外, PCA假设数据各主特征是分布在正交方向上, 如果在非正交方向上存在几个方差较大的方向, PCA的效果就大打折扣了, 并且PCA是一种无参数技术, 便于通用实现,但是本身无法个性化的优化.
主曲线
上面的内容都属于科普, 主要是看两篇关于主曲线的论文:
- DOI: 10.1145/3139958.3139966 来自于 SIGSPATIAL’17
- Ozertem U, Erdogmus D. Locally defined principal curves and surfaces[J]. Journal of Machine learning research, 2011, 12(Apr): 1249-1286.
Deriving Double-Digitized Road Network Geometry from Probe Data